Shuffle涉及到三方面问题:Shuffle write写过程,中间数据记录过程以及Shuffle read读过程,上面几节我们分析了write和中间记录过程,本文将聚焦在Shuffle read部分。ShffuleRead什么时候进行数据读取?ShuffleMap产生的数据如何拉取过来?拉取过来的数据如何存储和处理?本节我将通过源码分析来解答这些问题。
问题
- ShuffleRDD是何时产生的?
- Shuffle-ReduceTask在什么时候开始执行,是等parent stage中的一个ShuffleMapTask 执行完还是等全部ShuffleMapTasks执行完?
- Shuffle-ReduceTask怎么获得当前Reduce任务所需要数据的存放位置?
- Shuffle-ReduceTask一边获取数据一边处理还是一次性获取完再处理?
- Shuffle-ReduceTask获取到的数据存放到哪里,内存?磁盘?如何协调的?
- Shuffle-ReduceTask如何处理具有聚合,排序要求的算子?
ShuffleRDD
ShuffleRDD是如何产生的
首先我们来看下ShuffleRDD是如何产生的,我们知道,RDD的计算链根据Shuffle被切分为不同的stage,一个stage的开始阶段一般是读取上一阶段的数据<数据有可能是从hdfs读取的HadoopRDD或者是上一个Shuffle产出的RDD,如果是上一个shuffle的结果,则该stage读取数据的过程其实就是reduce过程>,然后经过该stage的计算链后得到结果数据,再然后就会把这些数据写入到磁盘供下一个stage读取。我们来看一个使用简单的Shuffle算子的例子,我们创建一个RDD,然后使用groupByKey进行分组,然后对每个key对应的数据拿取数据迭代器,最后使用collect这个action算子来触发真实计算,如下所示:scala> var rdd1 = sc.makeRDD(Array(("A",0),("A",2),("B",1),("B",2),("C",1))) rdd1: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> val rdd2 = rdd1.groupByKey()
rdd2: org.apache.spark.rdd.RDD[(String, Iterable[Int])] = ShuffledRDD[1] at groupByKey at
scala> val rdd3 = rdd2.map(row => row._2)
rdd3: org.apache.spark.rdd.RDD[Iterable[Int]] = MapPartitionsRDD[2] at map at
scala> rdd3.collect
res1: Array[Iterable[Int]] = Array(CompactBuffer(0, 2), CompactBuffer(2, 1), CompactBuffer(1))
我们在Spark UI上面看下该job是如何划分stage的,可以看出来划分了两个stage,groupByKey算子由于涉及到Shuffle操作,将这个job划分为两个stage,Stage 0对应的ShuffleMapTask,Stage 1对应的是ShuffleReadTask也有可能是下一个Shuffle的MapTask,如下所示:<br />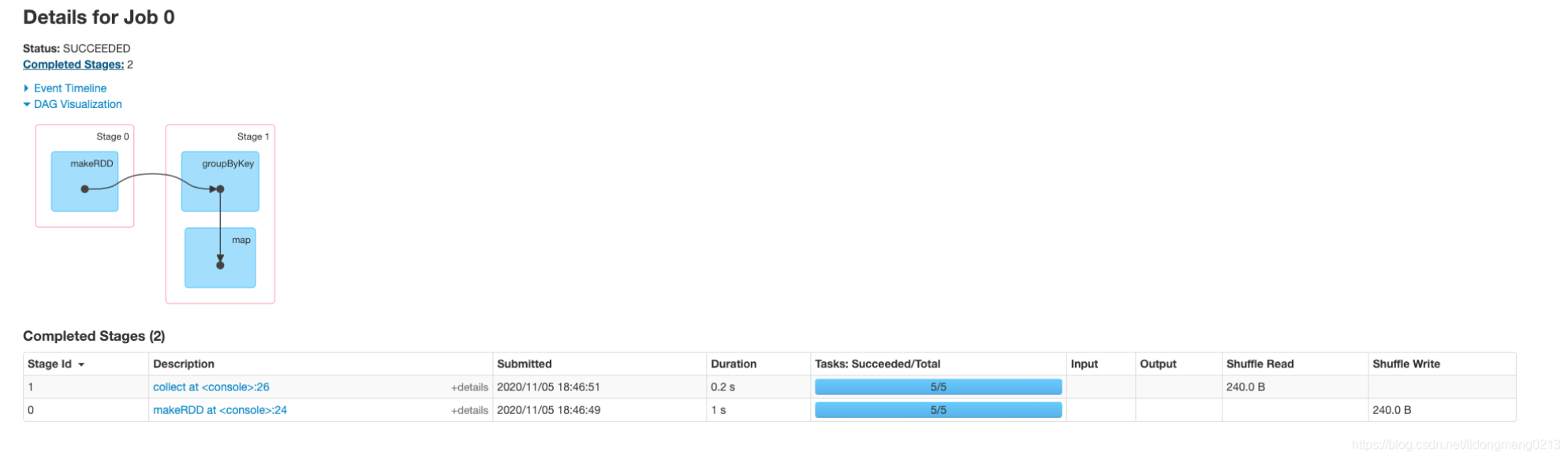<br />Stage 0主要是读取RDD,然后按照key进行合并数据,写入到磁盘中:<br /><br />Stage 1是读取ShuffleMapTask的数据,然后进行map算子计算,获取数据,可以看出来这个时候ReduceTask的初始数据RDD是ShuffleRDD。<br /><br />我们最后来看下执行toDebugString打印相应RDD的Lineage,和上面DAG图是一样的:
scala> rdd3.toDebugString
res0: String =
(5) MapPartitionsRDD[2] at map at
| ShuffledRDD[1] at groupByKey at
+-(5) ParallelCollectionRDD[0] at makeRDD at
**所以我们可以看出来,在Shuffle产生时候,上游进行ShuffleMapTask,写入数据到文件中,下游stage读取这些数据形成的RDD即为ShuffleRDD。**
<a name="DGIYN"></a>
### ShuffleRDD何时去读取数据
在MapReduce中,可以通过设置mapred.reduce.slowstart.completed.maps来控制map端任务执行到多少比例后可以启动reduce端任务的计算,Spark中是不是也是一定比例的ShuffleMapTask结束后就可以进行Reduce任务执行,从而拉取数据,答案是否定的,Spark中Shuffle将job划分为多个stage,一个stage要想开始执行,必须满足它所依赖的stages都执行完成,也就是ShuffleMapTask计算结束后。
<a name="Z8Zzq"></a>
### ShuffleRDD是如何得到数据
ShuffleRDD继承自RDD,实现了compute逻辑,实现了如何获取数据的,源码如下,可以看出来先通过ShuffleManager获取相应的Reader<默认是BlockStoreShuffleReader>,然后通过read方法,获取数据迭代器,给下游算子计算使用。
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
// 获取第一个依赖
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
// 首先调用SortShuffleManager的getReader()方法获取BlockStoreShuffleReader
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
// 调用BlockStoreShuffleReader的read()方法获取map任务输出的Block并在reduce端进行聚合或排序
.read()
.asInstanceOf[Iterator[(K, C)]]
}
我们再来看下Reader的初始化操作:
// 用于获取对map任务输出的分区数据文件中从startPartition到endPartition-1范围内的数据
// 进行读取的读取器(即BlockStoreShuffleReader),供reduce任务使用。
override def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C] = {
new BlockStoreShuffleReader(
handle.asInstanceOf[BaseShuffleHandle[K, _, C]], startPartition, endPartition, context)
}
另外我们看下ShuffleRDD中的一些成员变量,记录了是否包含自定义的序列化器,是否需要聚合数据,是否需要排序,是否进行了mapSide聚合操作,这些都是上游算子定义的:
private var userSpecifiedSerializer: Option[Serializer] = None
private var keyOrdering: Option[Ordering[K]] = None
private var aggregator: Option[Aggregator[K, V, C]] = None
private var mapSideCombine: Boolean = false
def setSerializer(serializer: Serializer): ShuffledRDD[K, V, C] = {
this.userSpecifiedSerializer = Option(serializer)
this
}
def setKeyOrdering(keyOrdering: Ordering[K]): ShuffledRDD[K, V, C] = {
this.keyOrdering = Option(keyOrdering)
this
}
def setAggregator(aggregator: Aggregator[K, V, C]): ShuffledRDD[K, V, C] = {
this.aggregator = Option(aggregator)
this
}
def setMapSideCombine(mapSideCombine: Boolean): ShuffledRDD[K, V, C] = {
this.mapSideCombine = mapSideCombine
this
}
<a name="lHYEQ"></a>
### 算子例子源码分析
我们来看下groupByKey和reduceByKey的实现,可以看出来都调用了combineByKeyWithClassTag在指定的分区器和当前RDD的分区器不一致时候会创建ShuffleRDD,并设置相应的属性信息。
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
// 不指定mapSideCombine,createCombiner只是对数据的包装,
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)] = self.withScope {
// 用combineByKey算子来实现;createCombiner是(v: V) => v,mergeValue是func,mergeCombiners是func
combineByKeyWithClassTag[V]((v: V) => v, func, func, partitioner)
}
def combineByKeyWithClassTag[C](createCombiner: V => C, mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C, partitioner: Partitioner, mapSideCombine: Boolean = true,
serializer: Serializer = null)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
….
// 创建聚集器
val aggregator = new Aggregator[K, V, C](
self.context.clean(createCombiner),
self.context.clean(mergeValue),
self.context.clean(mergeCombiners))
// 判断传入分区器是否相同
if (self.partitioner == Some(partitioner)) {
// 如果分区器相同,直接使用聚集器将迭代器中的数据进行聚合,返回InterruptibleIterator迭代器
self.mapPartitions(iter => {
val context = TaskContext.get()
new InterruptibleIterator(context, aggregator.combineValuesByKey(iter, context))
}, preservesPartitioning = true)
} else {
// 分区器不同,则创建ShuffledRDD
new ShuffledRDD[K, V, C](self, partitioner)
.setSerializer(serializer)
.setAggregator(aggregator)
.setMapSideCombine(mapSideCombine)
}
}
<a name="k6rf6"></a>
## BlockStoreShuffleReader
<a name="vifsT"></a>
### 初始化
BlockStoreShuffleReader继承于ShuffleReader实现了read读取数据的方法,包含以下成员变量:
1. handle记录Shuffle的元信息,有多少map,以及ShuffleDependency信息;
2. startPartition和endPartition表示所要获取的ReduceId区间的数据,[startPartition, endPartition);
3. serializerManager对数据进行反序列化;
4. blockManager读取数据块信息;
5. mapOutputTracker提供ShuffleMapTask产生数据的位置信息。
private[spark] class BlockStoreShuffleReader[K, C](
handle: BaseShuffleHandle[K, _, C],
startPartition: Int,
endPartition: Int,
context: TaskContext,
serializerManager: SerializerManager = SparkEnv.get.serializerManager,
blockManager: BlockManager = SparkEnv.get.blockManager,
mapOutputTracker: MapOutputTracker = SparkEnv.get.mapOutputTracker)
extends ShuffleReader[K, C] with Logging {
…
}
<a name="qcnlZ"></a>
### 整体流程
我们来看下read的整体流程:
1. 首先新建ShuffleBlockFetcherIterator获取数据迭代器,会返回(blockId, inputStream)的数据迭代器;
2. 对每个block数据进行压缩和加密操作,是通过serializerManager进行的,对每个block数据进行反序列化,反序列化输入流成为<K,V>数据迭代器;
3. 对迭代器添加监控和数据处理完成后的清洗函数处理工作;
4. 如果要进行聚合操作,会对各个map的当前reduceId的数据进行聚合;
5. 如果需要排序,对聚合后的数据进行排序操作。
override def read(): Iterator[Product2[K, C]] = {
// 伴随着对本地和远端的数据块的获取
val blockFetcherItr = new ShuffleBlockFetcherIterator(…)
// 对各个数据块的输入流进行压缩和加密
val wrappedStreams = blockFetcherItr.map { case (blockId, inputStream) =>
serializerManager.wrapStream(blockId, inputStream)
}
val serializerInstance = dep.serializer.newInstance()
// 给每个流创建一个key/value的迭代器
val recordIter = wrappedStreams.flatMap { wrappedStream =>
// 进行反序列化
serializerInstance.deserializeStream(wrappedStream).asKeyValueIterator
}
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]](
recordIter.map { record =>
readMetrics.incRecordsRead(1)
record
},
context.taskMetrics().mergeShuffleReadMetrics())
// 创建可中断的迭代器,能够支持TaskAttempt的取消操作
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)
// 处理可能存在的聚合迭代
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
....
} else {
...
}
// 是否排序
dep.keyOrdering match {
case Some(keyOrd: Ordering[K]) =>
...
case None =>
...
}
}
从这个流程上面,我们应该有这样几个疑问:
1. 数据从哪里来的?
2. 每个block的数据如何获取的?
3. 聚合时候内部是如何处理的?
4. 排序时候Spark内部是如何处理的?
我们来一一解答这些问题。
<a name="us4n6"></a>
### 数据位置获取
我们要读取数据,首先我们来看下我们如何获得想要的数据的存放位置? 这个位置是靠mapOutputTracker来拿取的,具体的拿取过程可以参考[Spark Shuffle源码分析系列之MapOutputTracker](https://blog.csdn.net/lidongmeng0213/article/details/109221861)中MapOutputTrackerWorker部分,文中我们分析了如何获取需要的ShuffleID的状态信息,没有讲解如何转换为ShuffleReader需要的数据格式,我们来看下这部分是如何转换的:
1. statuses是获取到的当前shuffleId对应的每个map的状态信息,包含了block所在的位置,以及各个reduce分区的文件大小信息;
2. 遍历每一个map task的结果信息,对于需要的reduce分区部分,组装元信息为<ShuffleBlockId<包含了shuffleId, mapId和reduceId>, partition对应的长度>,然后放到Block所在的executor中。
private def convertMapStatuses(shuffleId: Int, startPartition: Int, endPartition: Int,
statuses: Array[MapStatus]): Seq[(BlockManagerId, Seq[(BlockId, Long)])] = {
val splitsByAddress = new HashMap[BlockManagerId, ArrayBuffer[(BlockId, Long)]]
// 遍历MapStatus集合
for ((status, mapId) <- statuses.zipWithIndex) {
if (status == null) { // 状态为空,抛出异常
throw new MetadataFetchFailedException(shuffleId, startPartition, errorMessage)
} else {
for (part <- startPartition until endPartition) { // 遍历每个对应的分区
// 添加到splitsByAddress字典
splitsByAddress.getOrElseUpdate(status.location, ArrayBuffer()) +=
((ShuffleBlockId(shuffleId, mapId, part), status.getSizeForBlock(part)))
}
}
}
splitsByAddress.toSeq
}
<a name="Sx23S"></a>
### 块数据迭代器获取
ShuffleBlockFetcherIterator是获取当前ReduceTask所需要数据的迭代器,会将数据划分为两部分,一部分从本地获取数据如果本地有数据,一部分从远端获取如果远端有数据,最后以迭代器方式返回各个BlockId<ShuffleMapTask产生的ShuffleBlockId>对应的数据流,接下来我们分析下是如何划分块数据以及返回迭代器数据的。
<a name="ugxTA"></a>
#### 迭代器创建
ShuffleBlockFetcherIterator初始化是在BlockStoreShuffleReader的read方法中进行的,获取了数据的位置信息,以及指定了一批请求同时请求的最大字节数以及单次的最多请求数。
// org.apache.spark.shuffle.BlockStoreShuffleReader
override def read(): Iterator[Product2[K, C]] = {
// 伴随着对本地和远端的数据块的获取
val blockFetcherItr = new ShuffleBlockFetcherIterator(
context,
blockManager.shuffleClient,
blockManager,
// 获取当前reduce任务所需的map任务中间输出数据的BlockManager的BlockManagerId及每个数据块的BlockId与大小
mapOutputTracker.getMapSizesByExecutorId(handle.shuffleId, startPartition, endPartition),
// Note: we use getSizeAsMb when no suffix is provided for backwards compatibility
SparkEnv.get.conf.getSizeAsMb("spark.reducer.maxSizeInFlight", "48m") * 1024 * 1024,
SparkEnv.get.conf.getInt("spark.reducer.maxReqsInFlight", Int.MaxValue))
…
}
<a name="IeEkE"></a>
#### 成员变量
1. shuffleClient,用于从远端获取数据块的client,如果开启了外部Shuffle服务,则对应是ExternalShuffleClient,否则是NettyBlockTransferService,这部分在BlockManager分析时候讲到过;
2. blocksByAddress:是从MapOutTracker获取到当前处理的ReduceId对应的所有ShuffleMapTask各个map结果中属于当前Reduce的数据开始位置和大小,是通过reduceId和索引文件得到的,这部分在MapOutTracker中讲到过;
3. maxBytesInFlight表示一批请求同时请求的最大字节数,为了提高请求的并发度,保证至少向5个不同的节点发送请求获取数据,最大限度地利用各节点的资源,所以每个请求的字节数不能超过maxBytesInFlight的1/5,可以通过参数spark.reducer.maxMbInFlight来控制大小[默认为48MB];
4. maxReqsInFlight表示单次的最多请求数,此参数可以通过spark.reducer.maxReqsInFlight属性配置,默认为Integer.MAX_VALUE;
5. numBlocksToFetch表示ShuffleMapTask中产出数据中属于该ReduceTask处理数据的块的数目;
6. numBlocksProcessed表示目前已经处理过的Block数目,当其大于numBlocksToFetch时候表示已经拉取完了所有map产生的属于该reduce的数据;
7. localBlocks表示ShuffleMapTask的结果数据在当前机器上的数目,可以从本地获取,数据本地性,减少网络访问,加快处理速度;
8. remoteBlocks表示ShuffleMapTask的结果数据不在当前机器上的数目,需要通过外部Shuffle服务或者基于Netty的块传输服务来拉取远端的块数组;
9. results用于保存获取Block的结果信息(FetchResult);
10. fetchRequests获取Block的请求信息(FetchRequest)的队列,对外提供的数据迭代器就是从队列不断拿取请求。
final class ShuffleBlockFetcherIterator(
context: TaskContext,
shuffleClient: ShuffleClient,
blockManager: BlockManager,
blocksByAddress: Seq[(BlockManagerId, Seq[(BlockId, Long)])],
maxBytesInFlight: Long,
maxReqsInFlight: Int)
extends Iterator[(BlockId, InputStream)] with Logging {
private[this] var numBlocksToFetch = 0 // 一共要获取的Block数量
private[this] var numBlocksProcessed = 0 // 已经处理的Block数量
// 缓存了本地BlockManager管理的Block的BlockId。
private[this] val localBlocks = new ArrayBufferBlockId
// 缓存了远端BlockManager管理的Block的BlockId。
private[this] val remoteBlocks = new HashSetBlockId
// 用于保存获取Block的结果信息(FetchResult)
private[this] val results = new LinkedBlockingQueue[FetchResult]
// 当前正在处理的FetchResult。
@volatile private[this] var currentResult: FetchResult = null
// 获取Block的请求信息(FetchRequest)的队列。
private[this] val fetchRequests = new Queue[FetchRequest]
// 当前批次的请求的字节数。
private[this] var bytesInFlight = 0L
// 当前批次的请求的数量。
private[this] var reqsInFlight = 0
// ShuffleBlockFetcherIterator是否处于激活状态。 如果isZombie为true,则ShuffleBlockFetcherIterator处于非激活状态。
@GuardedBy(“this”)
private[this] var isZombie = false
}
<a name="CgKUK"></a>
#### 初始化
ShuffleBlockFetcherIterator在新建后会自行调用initialize进行初始化,主要是划分本地和远端数据,获取本地以及远端数据:
private[this] def initialize(): Unit = {
// 给TaskContextImpl添加任务完成的监听器,便于任务执行完成后调用cleanup()方法进行一些清理工作
context.addTaskCompletionListener(_ => cleanup())
// 划分从本地读取和需要远程读取的Block的请求
val remoteRequests = splitLocalRemoteBlocks()
// 远端数据获取;将FetchRequest随机排序后存入fetchRequests
fetchRequests ++= Utils.randomize(remoteRequests)
// 发送请求
fetchUpToMaxBytes()
val numFetches = remoteRequests.size - fetchRequests.size
// 本地数据Block获取
fetchLocalBlocks()
}
<a name="KjfoW"></a>
##### 切分数据源请求
splitLocalRemoteBlocks方法确定数据的读取策略,localBlocks变量记录在本地机器的BlockID,remoteBlocks变量则用于记录所有在远程机器上的BlockID。远程数据块被分割成最大为maxSizeInFlight大小的FetchRequests,步骤如下:
1. 首先计算每个请求的最大请求数据大小,是max(maxBytesInFlight / 5, 1L),这是为了提高请求的并发度,保证至少向5个不同的节点发送请求获取数据,最大限度地利用各节点的资源;
2. 遍历所有存储mapTask的结果的executor,如果与当前executor相同说明可以本地获取数据,将其添加到记录本地块的localBlocks中,块id包含了ShuffleId+mapId+reduceId,根据索引文件,可以快速定位到需要的的数据段,后面通过BlockManager来读取相应块的数据信息;
3. 如果是远端机器,则遍历每个块,由于涉及到网络请求,为了提高系统性能,采用批量发送请求,当一批次的块的大小大于targetRequestSize时候,会进行构建一个FetchRequest,最后未加入部分再构建一个FetchRequest。
// 划分从本地读取和需要远程读取的Block的请求
private[this] def splitLocalRemoteBlocks(): ArrayBuffer[FetchRequest] = {
// 每个远程请求的最大尺寸,等于maxBytesInFlight的1/5或者1
val targetRequestSize = math.max(maxBytesInFlight / 5, 1L)
// 缓存需要远程请求的FetchRequest对象
val remoteRequests = new ArrayBuffer[FetchRequest]
var totalBlocks = 0 // 统计所有Block的总大小
// 遍历已经在blocksByAddress中缓存的按照BlockManagerId分组的BlockId
// 类型为(BlockManagerId, Seq[(BlockId, Long)])
for ((address, blockInfos) <- blocksByAddress) {
totalBlocks += blockInfos.size
if (address.executorId == blockManager.blockManagerId.executorId) { // block list在本地
// 将BlockManagerId对应的所有大小不为零的BlockId存入localBlock
localBlocks ++= blockInfos.filter(_._2 != 0).map(_._1)
// 将所有大小不为零的BlockId存入local Blocks
numBlocksToFetch += localBlocks.size
} else { // 远端的Block
val iterator = blockInfos.iterator
// 当前累加到curBlocks中的所有Block的大小,用于保证每个远程请求的尺寸不超过targetRequestSize的限制
var curRequestSize = 0L
// 远程获取的累加缓存,用于保存每个远程请求的尺寸不超过targetRequestSize的限制,
// 实现批量发送请求,以提高系统性能;注意,此时的批量请求是发送到同一个BlockManager上的,只是包含了多个数据块的BlockId。
var curBlocks = new ArrayBuffer[(BlockId, Long)]
while (iterator.hasNext) {
val (blockId, size) = iterator.next()
if (size > 0) {
// 将所有大小大于零的BlockId和size累加到curBlocks
curBlocks += ((blockId, size))
// 将所有大小不为零的BlockId存入remoteBlocks
remoteBlocks += blockId
numBlocksToFetch += 1
// 增加当前请求要获取的Block的总大小
curRequestSize += size
} else if (size < 0) {
throw new BlockException(blockId, "Negative block size " + size)
}
// 每当curRequestSize >= targetRequestSize, 就作为一个批次生成一个新的FetchRequest,放入remoteRequests
if (curRequestSize >= targetRequestSize) {
// 新建FetchRequest放入remoteRequests
remoteRequests += new FetchRequest(address, curBlocks)
// 新建curBlocks,将curRequestSize置为0,为生成下一个FetchRequest做准备
curBlocks = new ArrayBuffer[(BlockId, Long)]
curRequestSize = 0
}
}
if (curBlocks.nonEmpty) { // 对剩余需要拉取的数据块新建FetchRequest放入remoteRequests
remoteRequests += new FetchRequest(address, curBlocks)
}
}
}
remoteRequests
}
<a name="PqdQp"></a>
##### 数据拉取结果
拉取结果是用FetchResult进行抽象的,包含了块id以及块所在机器信息。本地块数据是通过blockManager进行拉取的,远端块数据是通过shuffleClient拉取的,都有成功或者失败的可能性。
private[storage] sealed trait FetchResult {
val blockId: BlockId
val address: BlockManagerId
}
成功时候会返回SuccessFetchResult结果,包含了块Id信息,块在的机器信息,块中数据大小信息<估算>,以及一个装载数据的Buffer,最后还有一个isNetworkReqDone是本次拉取的结果是否是最后的结果。
private[storage] case class SuccessFetchResult(
blockId: BlockId, // 拉取的块id
address: BlockManagerId, // 机器信息
size: Long, // 估算大小
buf: ManagedBuffer, // 装载数据的Buffer
isNetworkReqDone: Boolean) extends FetchResult {
require(buf != null)
require(size >= 0)
}
失败时候会返回FailureFetchResult结果,包含了块Id信息,块在的机器信息,以及失败的异常。
private[storage] case class FailureFetchResult(
blockId: BlockId,
address: BlockManagerId,
e: Throwable)
extends FetchResult
<a name="suHbB"></a>
##### 本地数据读取
localBlocks记录了本地的块信息,迭代每个块,使用本地的BlockManager读取块信息,具体是由IndexShuffleBlockResolver的getData来获取数据流的,只是获取一个文件的读取流,构造成FileSegmentManagedBuffer,这时候并没有真正的读取数据到内存。
private[this] def fetchLocalBlocks() {
// 得到localBlocks数组的迭代器
val iter = localBlocks.iterator
// 迭代每一个BlockId
while (iter.hasNext) {
// 获取BlockId
val blockId = iter.next()
try {
// 获取Block数据,创建SuccessFetchResult对象,并添加到results中
val buf = blockManager.getBlockData(blockId)
buf.retain()
// 创建SuccessFetchResult对象,添加到results中
results.put(new SuccessFetchResult(blockId, blockManager.blockManagerId, 0, buf, false))
} catch {
case e: Exception =>
results.put(new FailureFetchResult(blockId, blockManager.blockManagerId, e))
return
}
}
}
<a name="Qrbdz"></a>
##### 远端数据读取
1. fetchRequests不为空,表示还有远程请求<一个请求可能包含一个机器上面的多个块>需要发送;
2. bytesInFlight为0,表示当前正在拉取的字节数为0;或者reqsInFlight小于规定的最大请求-1,表示还可以发送请求,并且当前正在拉取的字节数bytesInFlight与fetchRequests队首请求拉取的字节数之和小于最大的字节请求数目,则可以发送请求。
private def fetchUpToMaxBytes(): Unit = {
while (fetchRequests.nonEmpty && (bytesInFlight == 0 || (reqsInFlight + 1 <= maxReqsInFlight &&
bytesInFlight + fetchRequests.front.size <= maxBytesInFlight))) {
// 发生FetchRequest远程请求,获取数据块中间结果
sendRequest(fetchRequests.dequeue())
}
}
我们再来看下具体的请求发送sendRequest是如何进行的,主要是通过ShuffleClient的fetchBlocks拉取当前请求的块集合,并且注册监听器,如果某个块拉取成功会构建SuccessFetchResult加入到结果中,如果拉取失败则构建FailureFetchResult将入到结果中,这个实际都没有触发真正的读取到内存,要通过后面的迭代器给外界访问时候才进行最终的拉取。
private[this] def sendRequest(req: FetchRequest) {
bytesInFlight += req.size // 将请求的所有Block的大小累加到bytesInFlight
reqsInFlight += 1 // 将reqsInFlight累加一
// [BlockId所对应的文件名, 对应字节数]字典
val sizeMap = req.blocks.map { case (blockId, size) => (blockId.toString, size) }.toMap
// 还需要拉取的数据块的Set集合
val remainingBlocks = new HashSetString ++= sizeMap.keys
// BlockId所对应的文件名的集合
val blockIds = req.blocks.map(.1.toString)
// 批量下载远端的数据块
val address = req.address
// 使用ShuffleClient的fetchBlocks()方法拉取
// 如果部署了外部的Shuffle服务,则需要配置spark.shuffle.service.enabled属性为true[默认是false],此时将创建ExternalShuffleClient。
// 默认情况下,NettyBlockTransferService会作为Shuffle的客户端。
shuffleClient.fetchBlocks(address.host, address.port, address.executorId, blockIds.toArray,
new BlockFetchingListener {
// 下载成功后会调用该方法
// blockId是ShuffleBlockId包含了需要读取数据的partiton,可以通过indexResolve得到偏移量,只拿取需要的数据
override def onBlockFetchSuccess(blockId: String, buf: ManagedBuffer): Unit = {
ShuffleBlockFetcherIterator.this.synchronized {
if (!isZombie) { // 结果封装为SuccessFetchResult放入results中
buf.retain()
remainingBlocks -= blockId
// 将结果封装为SuccessFetchResult放入到results中
results.put(new SuccessFetchResult(BlockId(blockId), address, sizeMap(blockId), buf, remainingBlocks.isEmpty))
}
}
}
override def onBlockFetchFailure(blockId: String, e: Throwable): Unit = {
results.put(new FailureFetchResult(BlockId(blockId), address, e))
}
})
}
<a name="rEkS9"></a>
#### 块数据迭代器
完成了数据拆分和本地以及远端数据拉取连接的建立,就可以对外提供数据了,迭代器返回了(blockId, InputStream)的二元组,numBlocksToFetch记录了需要拉取block的总数目,numBlocksProcessed是已经处理好块的数目。
// 取决于numBlocksProcessed是否小于numBlocksToFetch
override def hasNext: Boolean = numBlocksProcessed < numBlocksToFetch
// 获取下一个[BlockId, InputStream]
override def next(): (BlockId, InputStream) = {
numBlocksProcessed += 1
val startFetchWait = System.currentTimeMillis()
// 从results队列中取出一个FetchResult
currentResult = results.take()
val result = currentResult
val stopFetchWait = System.currentTimeMillis()
shuffleMetrics.incFetchWaitTime(stopFetchWait - startFetchWait)
// 根据FetchResult的类型匹配SuccessFetchResult
// 这一次的匹配主要是维护拉取成功的请求所关联的各类记录字典的更新
result match {
// 拉取成功的结果
case SuccessFetchResult(_, address, size, buf, isNetworkReqDone) =>
// 维护度量信息
if (address != blockManager.blockManagerId) {
shuffleMetrics.incRemoteBytesRead(buf.size)
shuffleMetrics.incRemoteBlocksFetched(1)
}
// 维护正在拉取的数据块字节数计数
bytesInFlight -= size
if (isNetworkReqDone) { // 如果本次拉取的结果是否是最后的结果
// 将正在拉取的请求计数减1
reqsInFlight -= 1
logDebug("Number of requests in flight " + reqsInFlight)
}
case _ =>
}
// 由于限制了远程频率,因此可能会有未发送的请求,需要再次发送远程拉取请求
fetchUpToMaxBytes()
// 根据FetchResult的类型匹配FailureFetchResult或SuccessFetchResult
result match {
// 拉取失败
case FailureFetchResult(blockId, address, e) =>
// 抛出异常
throwFetchFailedException(blockId, address, e)
// 拉取成功
case SuccessFetchResult(blockId, address, _, buf, _) =>
try {
// 返回BlockId与BufferReleasingInputStream的元组
(result.blockId, new BufferReleasingInputStream(buf.createInputStream(), this))
} catch {
case NonFatal(t) =>
// 抛出异常
throwFetchFailedException(blockId, address, t)
}
}
}
<a name="GQh0o"></a>
#### 总结
从上面分析,可以看出来,ShuffleBlockFetcherIterator将不同块进行拆分本地和远端,然后建立连接,读取得到结果,迭代器是不断迭代块,不断读取块信息,然后继续后续处理,所以数据并不是一次性读取到内存中再进行处理的,而是一边fetch数据,一边处理。