Flink几种提交任务的模式及源码分析
一、模式
1. Yarn Session模式
此模式下需要提前使用flink命令预先创建一个Yarn上的常驻应用,后续可以指定JobManager的地址向集群提交任务。
# 创建flink yarn session集群
./bin/yarn-session.sh -jm <JobManager内存大小> -tm <TaskManager内存大小> -yd -n <TaskManagers数量> -s <每个TaskManager的slot数量> -at <指定YARN集群的Application Type> -nm <指定YARN集群的Application Name>
# 向flink yarn session集群提交任务
./bin/flink run -m <TaskManager Adress:Port> -p <并行度> path/to/your-job.jar
2. Per Job模式
此模式下不需要提前创建集群,提交任务时会为一个作业单独创建一个集群,作业结束集群自动释放。
# 使用Per Job方式提交任务
./bin/flink run -m yarn-cluster -yjm <JobManager内存> -ytm <TaskManager内存> -yn <TaskManager数量> -ys <每个TaskManager的slot数量> path/to/your-job.jar
3. Application 模式
Application模式会将整个Flink应用作为一个YARN任务提交。与Per-Job模式类似,区别在于Application模式是一种应用级别的提交方式。
# 使用Application方式提交任务
./bin/flink run-application -t yarn-application -Djobmanager.memory.process.size=<JobManager内存> -Dtaskmanager.memory.process.size=<TaskManager内存> -Dparallelism.default=<并行度> path/to/your-job.jar
4. 总结
| 模式 | 特点 | 适用场景 | 优势 | 局限 |
|---|---|---|---|---|
| Session | 共享集群,多个作业使用同一集群 | 小规模测试、开发环境 | 资源利用率高,适合短任务 | 隔离性差,作业间相互影响 |
| Per-Job | 每个作业独立集群,作业完成即释放 | 生产环境关键任务,对隔离性要求高 | 资源隔离性强,作业间互不影响 | 每次启动和释放集群有开销 |
| Application | 整个应用程序作为一个整体提交,应用完成即释放 | 独立的批处理应用程序,隔离性要求高的生产环境 | 资源隔离性好,集群生命周期灵活 | 不适合频繁提交的小任务或测试作业 |
⚠️ Yarn Session 和 Per Job 模式执行 main 方法的位置是客户端所在机器,是不传入 JobGraph 的。社区考虑到在客户端执行 main 方法来获取 flink 运行时所需的依赖项,并生成 JobGraph,并将依赖项和 JobGraph 发送到集群的一系列过程中,由于需要大量的网络带宽下载依赖项并将二进制文件发送到集群,会造成客户端消耗大量的资源。尤其在大量用户共享客户端时,问题更加突出。因此,社区提出新的部署方式 Application 模式解决该问题。
Application 模式下,用户程序的 main 方法将在集群中而不是客户端运行,用户将程序逻辑和依赖打包进一个可执行的 jar 包里,集群的入口程序 (ApplicationClusterEntryPoint) 负责调用其中的 main 方法来生成 JobGraph。Application 模式为每个提交的应用程序创建一个集群,该集群可以看作是在特定应用程序的作业之间共享的会话集群,并在应用程序完成时终止。在这种体系结构中,Application 模式在不同应用之间提供了资源隔离和负载平衡保证。在特定一个应用程序上,JobManager 执行 main() 可以节省所需的 CPU 周期,还可以节省本地下载依赖项所需的带宽。
二、 源码
# flink脚本的入口,可以看到是先执行CliFrontend的main方法
exec "${JAVA_RUN}" $JVM_ARGS $FLINK_ENV_JAVA_OPTS "${log_setting[@]}" -classpath "`manglePathList "$CC_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS"`" org.apache.flink.client.cli.CliFrontend "$@"
static int mainInternal(final String[] args) {
EnvironmentInformation.logEnvironmentInfo(LOG, "Command Line Client", args);
// 1. find the configuration directory
final String configurationDirectory = getConfigurationDirectoryFromEnv();
// 2. load the global configuration
final Configuration configuration =
GlobalConfiguration.loadConfiguration(configurationDirectory);
// 3. load the custom command lines
final List<CustomCommandLine> customCommandLines =
loadCustomCommandLines(configuration, configurationDirectory);
int retCode = INITIAL_RET_CODE;
try {
final CliFrontend cli = new CliFrontend(configuration, customCommandLines);
CommandLine commandLine =
cli.getCommandLine(
new Options(),
Arrays.copyOfRange(args, min(args.length, 1), args.length),
true);
Configuration securityConfig = new Configuration(cli.configuration);
DynamicPropertiesUtil.encodeDynamicProperties(commandLine, securityConfig);
SecurityUtils.install(new SecurityConfiguration(securityConfig));
retCode = SecurityUtils.getInstalledContext().runSecured(() -> cli.parseAndRun(args));
} catch (Throwable t) {
final Throwable strippedThrowable =
ExceptionUtils.stripException(t, UndeclaredThrowableException.class);
LOG.error("Fatal error while running command line interface.", strippedThrowable);
strippedThrowable.printStackTrace();
}
return retCode;
}
主要关注loadCustomCommandLines和parseAndRun方法,前者依次添加GenericCli,FlinkYarnSessionCli,DefaultCli,后面根据isActive方法按顺序选择。
parseAndRun主要执行方法,代码如下:
//由于命令是flink run所以走到ACTION_RUN中
switch (action) {
case ACTION_RUN:
run(params);
return 0;
//..省略
}
//run方法中主要关注
validateAndGetActiveCommandLine,其主要功能为根据输入的命令获取客户端类型
getEffectiveConfiguration,会调用客户端实现的toConfiguration方法,以FlinkYarnSessionCli为例,方法内会组装jm,tm,slot的一些参数等等
1. 如果是Application模式,会初始化一个ApplicationDeployer用来部署集群,重点关注deployer.run()
public <ClusterID> void run(
final Configuration configuration,
final ApplicationConfiguration applicationConfiguration)
throws Exception {
checkNotNull(configuration);
checkNotNull(applicationConfiguration);
LOG.info("Submitting application in 'Application Mode'.");
final ClusterClientFactory<ClusterID> clientFactory =
clientServiceLoader.getClusterClientFactory(configuration);
try (final ClusterDescriptor<ClusterID> clusterDescriptor =
clientFactory.createClusterDescriptor(configuration)) {
final ClusterSpecification clusterSpecification =
clientFactory.getClusterSpecification(configuration);
clusterDescriptor.deployApplicationCluster(
clusterSpecification, applicationConfiguration);
}
}
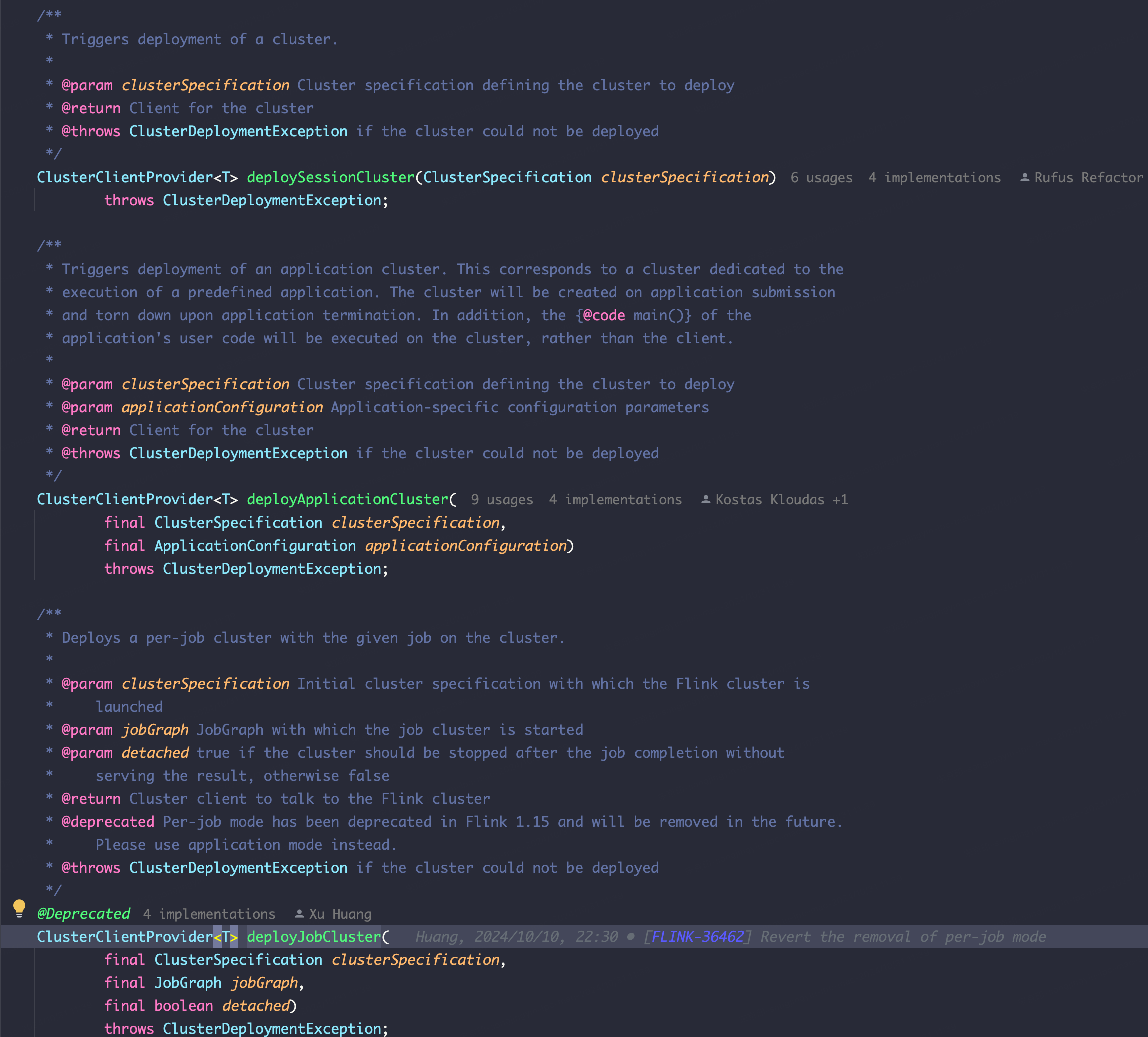
可以看到其主要逻辑为部署Flink集群,并提交作业,看一下接口注释,刚好印证前文说的用户的main方法执行地点不是在用户提交的客户端
/**
* Triggers deployment of an application cluster. This corresponds to a cluster dedicated to the
* execution of a predefined application. The cluster will be created on application submission
* and torn down upon application termination. In addition, the {@code main()} of the
* application's user code will be executed on the cluster, rather than the client.
*/
2. 如果是Flink Yarn Session和Per Job模式,则会走run方法中的另一分支,主要关注executeProgram方法,其主要功能为进入用户的主类代码
直接在用户提交的客户端执行main方法
三种方法入口接口