一、针对Spark Thrift Server
Spark Thrift Server是Apache Spark社区基于HiveServer2实现的一个Thrift服务,旨在无缝兼容HiveServer2。它通过JDBC接口将Spark SQL的能力以纯SQL的方式提供给终端用户。这种“开箱即用”的模式可以最大化地降低用户使用Spark的障碍和成本。但同时Spark Thrift Server也带来了很多局限性:
Driver 单点问题
整个Spark thrift server以一个Spark任务的形式运行在YARN上,所有的请求都运行在一个Driver中,一旦Driver挂掉后,所有任务都会同时失败。
资源隔离问题
因为Spark thrift server是以Spark任务的形式运行在YARN上,因此提交的任务如果有跨队列提交需求的时候,Spark thrift server很难支撑,其次多个任务运行在同一个Driver之中,资源使用会相互影响,很难更精细化的进行资源的管理。
多租户局限
Spark thrift server从请求层面是可以支持多用户的,但是从架构层面来看Spark thrift server是一个运行在Yarn上的任务,它也有自己的Application Id有自己的任务提交者,因此它实际上是以一个超级管理员的身份运行,再做二次租户隔离,必然存在一定的资源安全问题。
高可用局限
Spark thrift server本身是没有高可用涉及的,因此它的高可用需要自行单独设计,且还得考虑客户端的兼容,例如Hive JDBC将HA信息存储在ZK中,而Spark thrift server没有这样的机制,因此高可用的实施成本较高。
所以Apache Kyuubi旨在解决上述问题,Kyuubi通过Thrift JDBC/ODBC接口为最终用户提供了一个纯SQL网关,可以使用预编程和可扩展的Spark SQL引擎操作大规模数据。这种“开箱即用”的模型最大限度地减少了最终用户在客户端使用Spark的障碍和成本。在服务器端,Kyuubi服务器和引擎的多租户架构为管理员提供了一种实现计算资源隔离、数据安全性、高可用性、高客户机并发性等的方法。
二、针对 Spark Shuffle
传统的 Shuffle 实现如上图中间部分所示,每个 Mapper 对 Shuffle Output 的数据,根据 Partition ID 做排序,然后把排序好的数据和索引写入本地盘。Shuffle Read 阶段,Reducer 从所有 Mapper 的 Shuffle 文件里读取属于自己的 Partition 数据。但这种实现有如下几个缺陷:
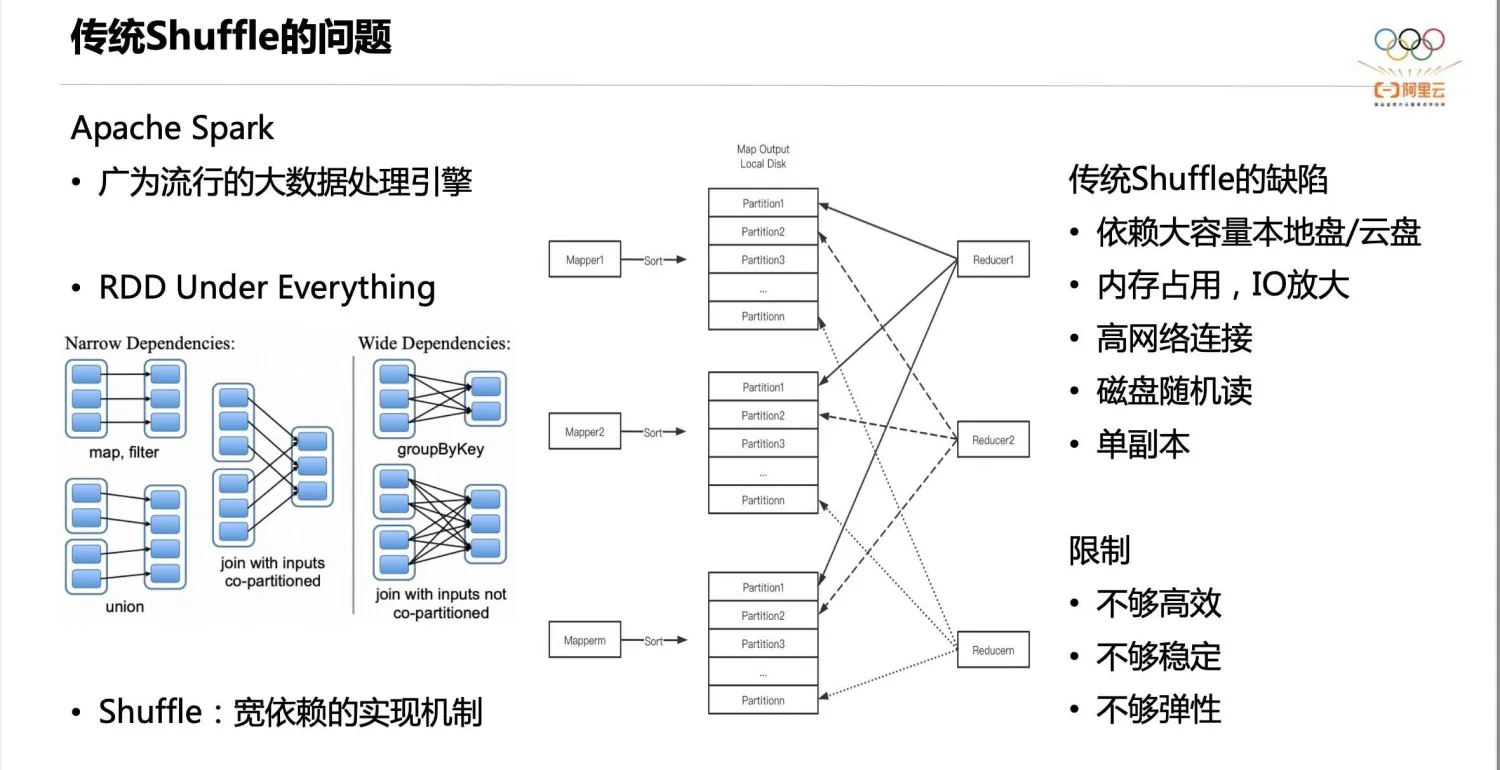
- 第一,依赖大容量的本地盘或云盘存储 Shuffle 数据,数据需要驻留直至消费完成。这就限制了存算分离,因为存算分离架构下,计算节点通常不希望有大容量的本地盘,希望计算结束就可以释放节点。
- 第二,Mapper 做排序会占用较大内存,甚至触发堆外排序,引入额外的磁盘 IO。
- 第三,Shuffle Read 有大量的网络连接,逻辑连接数是 m×n。
- 第四,存在大量的随机读盘。假设一个 Mapper 的 Shuffle 数据是 128M,Reducer 的并发是 2000,那么每个文件将会被读 2000 次,每次只随机读 64k,这就很容易达到磁盘 IOPS 的瓶颈。
- 第五,数据单副本,容错性不高。
开源社区对此开发出了Remote Shuffle Sevrvice解决方案,分别是阿里云的Apache Celeborn和腾讯的Apache Uniffle,目前两者的差别是 Celeborn 不支持 Tez 类型的任务,Uniffle不支持 Flink 类型的任务;另一个是元数据的存储,Uniffle存在于内存中,可能丢失数据。Celeborn通过raft协议强一致的存储在所有的master节点。考虑这里的元数据不需要强一致性,而且raft必然应对超大规模存在一些性能问题,公司内部暂时使用uniffle。uniffle可能丢数据的问题也可以通过汇报以及更好的故障恢复来解决。
三、针对 CPU 瓶颈
在社区发现了 Apache Kylin和 Intel 联合开发的项目Gluten,Gluten 项目旨在解决基于 Apache Spark 的数据负载场景中的 CPU 计算瓶颈。随着 IO 技术的提升,特别是SSD和万兆网卡的普及,CPU 计算瓶颈逐渐成为限制性能的主要因素。然而,基于 JVM 进行 CPU 指令优化相对困难,因为与其他本地语言(如C++)相比,JVM 提供的优化功能较少。本项目可以使 Spark 计算时使用本地的向量化引擎,如 ClickHouse,Velox等。具体可以参考这篇文章:
Gluten + Celeborn: 让 Native Spark 拥抱 Cloud Native