一、背景
在KA系统中需要解析FSImage来对整个HDFS系统分析其元数据(INode),来将数据可视化展示以及治理合并过多的小文件。
从代码中可以看到,使用OIV解析时分为三步:
loadDirectories(fin, sections, summary, conf);
loadINodeDirSection(fin, sections, summary, conf, refIdList);
output(conf, summary, fin, sections);
前两步load使用levelDB操作,levelDB的插入和查找是一个时间复杂度为O(logn)的操作,这一部分很难优化。最后一步是将所有INode信息输出到指定文件。如下是整个使用OIV解析时的日志,可以看到,前两步大概各耗时1小时左右,但在最后一步输出到指定文件的过程却用了快3个半到4个小时,本方案旨在针对最后一步输出步骤进行优化。
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/home/ke/local/hadoop-3.2.1/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/home/ke/local/tez-0.9.2/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2023-08-31 06:16:42,493 INFO offlineImageViewer.PBImageTextWriter: Loading string table
2023-08-31 06:16:42,505 INFO offlineImageViewer.FSImageHandler: Loading 88 strings
2023-08-31 06:16:42,565 INFO namenode.FSDirectory: GLOBAL serial map: bits=29 maxEntries=536870911
2023-08-31 06:16:42,565 INFO namenode.FSDirectory: USER serial map: bits=24 maxEntries=16777215
2023-08-31 06:16:42,565 INFO namenode.FSDirectory: GROUP serial map: bits=24 maxEntries=16777215
2023-08-31 06:16:42,565 INFO namenode.FSDirectory: XATTR serial map: bits=24 maxEntries=16777215
2023-08-31 06:16:42,565 INFO namenode.FSDirectory: DATACENTER serial map: bits=8 maxEntries=255
2023-08-31 06:16:42,569 INFO offlineImageViewer.PBImageTextWriter: Loading inode references
2023-08-31 06:16:42,569 INFO offlineImageViewer.FSImageHandler: Loading inode references
2023-08-31 06:16:42,574 INFO offlineImageViewer.FSImageHandler: Loaded 0 inode references
2023-08-31 06:16:42,574 INFO offlineImageViewer.PBImageTextWriter: Loading directories
2023-08-31 06:16:42,577 INFO offlineImageViewer.PBImageTextWriter: Loading directories in INode section.
2023-08-31 07:23:26,380 INFO offlineImageViewer.PBImageTextWriter: Found 64088370 directories in INode section.
2023-08-31 07:23:26,415 INFO offlineImageViewer.PBImageTextWriter: Finished loading directories in 4003841ms
2023-08-31 07:23:26,416 INFO offlineImageViewer.PBImageTextWriter: Loading INode directory section.
2023-08-31 08:45:03,974 INFO offlineImageViewer.PBImageTextWriter: Scanned 62838783 INode directories to build namespace.
2023-08-31 08:45:03,974 INFO offlineImageViewer.PBImageTextWriter: Finished loading INode directory section in 4897559ms
2023-08-31 08:45:04,008 INFO offlineImageViewer.PBImageTextWriter: Found 297626656 INodes in the INode section
2023-08-31 12:17:17,144 INFO offlineImageViewer.PBImageTextWriter: Outputted 297626656 INodes.
二、详细方案
FSImage中主要分为如下几个部分:
ondiskVersion: 1
layoutVersion: 4294967231
MAGIC_HEADER
sections {
name: "NS_INFO"
length: 34
offset: 8
}
sections {
name: "ERASURE_CODING"
length: 82
offset: 42
}
sections {
name: "INODE"
length: 2060
offset: 124
}
sections {
name: "INODE_DIR"
length: 129
offset: 2184
}
sections {
name: "FILES_UNDERCONSTRUCTION"
length: 42
offset: 2313
}
sections {
name: "SNAPSHOT"
length: 74
offset: 2355
}
sections {
name: "SNAPSHOT_DIFF"
length: 172
offset: 2429
}
sections {
name: "INODE_REFERENCE"
length: 24
offset: 2601
}
sections {
name: "SECRET_MANAGER"
length: 104
offset: 2625
}
sections {
name: "CACHE_MANAGER"
length: 7
offset: 2729
}
sections {
name: "STRING_TABLE"
length: 166
offset: 2736
}
FILESUMMARY
FILESUMMARY_LENGTH
从fsimage.proto和FSImage文件存储格式容易看到,除了文件头部校验(MAGIC_HEADER)和尾部文件索引(FILESUMMARY)等管理信息外,核心数据都是与文件系统目录树强相关。其中INODE和INODE_DIR是整个FSImage文件中最核心且也是规模最大的两个部分。
传统的加载完全按照串行方式执行:
(1)FSImage文件MD5值校验;
(2)读取FSImage文件的Summary数据;
(3)根据Summary的信息对每个Section依次读取、反序列化并构建内存数据结构;
注:FileSummary是对FSImage各个部分(Section)记录长度和偏移量的一种数据结构,本质上不保存FSImage的内容,最终获取内部的数据还是从fsImage的输入流中而来。
其中两个规模最大的两个Section即INODE和INODE_DIR。假设针对包含1亿个INode目录树的加载过程:需要先将1亿个INode从FSImage文件中按序读入并反序列化;完成后再将包含1亿条父子关系的INODE_DIR按序读入并反序列化,根据反序列化结果将所有子节点的引用按照二分查找的方式插入到父节点维护的数组中,到这里基本上目录树就构建起来(当然如果开启了如SNAPSHOT和Cache等特性的话,还需要将这部分数据加载完成),目录树构建完成后的内存组织情况详情参考NameNode内存全景。
三、并行加载优化
如果分析FSImage的整个加载过程,尤其是占比最大的INODE和INODE_DIR两个Section容易发现两个特点:
(1)INODE_DIR加载依赖INODE完成,即INODE和INODE_DIR两个Section之间存在严格的先后顺序;
(2)INODE和INODE_DIR两个Section内部Entry(目录树节点数据和节点之间父子关系信息)相互之间其实完全独立;
根据这两个特点,我们可以把INODE和INODE_DIR内部结构进一步做逻辑拆分,切割成多个INODE_SUB和多个INODE_DIR_SUB便于后续并行处理,其中:
将INODE和INODE_DIR两个Section进行逻辑拆分后其实不影响FSImage物理上的组织结构。为了能把INODE_SUB和INODE_DIR_SUB真正的分配给独立的线程且不重不漏,只需要在FSImage文件的FILESUMMARY索引里对逻辑SUB_SECTION(INODE_SUB+INODE_DIR_SUB)做好记录:偏移量+长度。
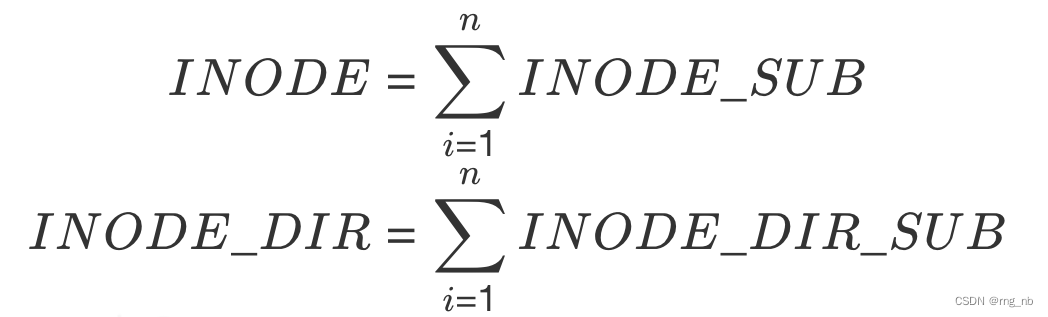
FSImage文件索引数据就绪后,当再次重启触发加载时,根据SUB_SECTION的个数及配置的加载线程数进行均衡拆分:
(1)确保多个线程之间分配到的SUB_SECTION尽可能相同;
(2)每一个SUB_SECTION只被一个线程独立消费;
通过这种方式拆分,FSImage的加载过程可以演变成如下图所示流程。
从整个优化思路可以看到,FSImage文件物理结构没有大调整,仅对FILESUMMARY做了简单扩展,核心数据组织上没有做任何改变,所以兼容能力上相对更好。
(1)使用原有逻辑加载新格式的FSImage文件时仅需要在读取FILESUMMARY时将INODE_SUB和INODE_DIR_SUB两类SECTION的索引过滤掉就可以,事实上在实现时也是这么处理的,即使是较早版本的实现也非常容易修复。
(2)并行逻辑加载原有格式FSImage文件时因为在FILESUMMARY中没有SUB_SECTION描述,所以即使升级到并行加载逻辑在真正执行时也是单线程完成。
整体上看,这种并行加载方案在效率和兼容性上能做到兼顾。
参考:HDFS-14617