一、 DataNode类的注释
/**********************************************************
* DataNode is a class (and program) that stores a set of
* blocks for a DFS deployment. A single deployment can
* have one or many DataNodes. Each DataNode communicates
* regularly with a single NameNode. It also communicates
* with client code and other DataNodes from time to time.
*
* DataNodes store a series of named blocks. The DataNode
* allows client code to read these blocks, or to write new
* block data. The DataNode may also, in response to instructions
* from its NameNode, delete blocks or copy blocks to/from other
* DataNodes.
*
* The DataNode maintains just one critical table:
* block-> stream of bytes (of BLOCK_SIZE or less)
*
* This info is stored on a local disk. The DataNode
* reports the table's contents to the NameNode upon startup
* and every so often afterwards.
*
* DataNodes spend their lives in an endless loop of asking
* the NameNode for something to do. A NameNode cannot connect
* to a DataNode directly; a NameNode simply returns values from
* functions invoked by a DataNode.
*
* DataNodes maintain an open server socket so that client code
* or other DataNodes can read/write data. The host/port for
* this server is reported to the NameNode, which then sends that
* information to clients or other DataNodes that might be interested.
*
**********************************************************/
翻译:
DataNode 是一个类(进程),它为 DFS 存储block集合。单个部署可以有一个或多个 DataNode.
每个 DataNode 有规律的与单个 NameNode 通信。它也会不定时与客户端代码和其他的 DataNode 通信。
DataNode 存储命名叫 block 的序列。DataNode 允许客户端代码读取这些 block,或者写新的 block 数据。DataNode 可以相应来自 NameNode 的指令,删除块,或者拷贝块 到/从 其他 DataNode 上。
DataNode 维护一个重要的表,block-> stream of bytes
这个信息被保存在本地磁盘,DataNode在启动时和启动之后会以一个频率向NameNode报告表的内容。
DataNode 花费一生,无穷尽的循环着,问NameNode 我要做什么。NameNode 不能直接连接 DataNode;NameNode 只是在 DataNode 请求的函数中,简单的回复一系列的值。
DataNode 维护一个开放的服务socket,因此客户端代码或其他的DataNode可以读写数据。
服务的 host/port 会报告给 NameNode,发送信息到可能感兴趣的客户端或其他的 DataNode。
二、Datanode 启动流程分析
这里会分阶段列出完整的调用栈,但只会分析比较重要的流程。
org.apache.hadoop.hdfs.server.datanode.DataNode#main
org.apache.hadoop.hdfs.server.datanode.DataNode#secureMain
org.apache.hadoop.hdfs.server.datanode.DataNode#createDataNode
org.apache.hadoop.hdfs.server.datanode.DataNode#instantiateDataNode
org.apache.hadoop.hdfs.server.datanode.DataNode#makeInstance
org.apache.hadoop.hdfs.server.datanode.DataNode#DataNode
org.apache.hadoop.hdfs.server.datanode.DataNode#startDataNode
在startDataNode这个方法里构造了RPC服务,或者直白的说DataNode本身就是一个RPC服务。具体方法请看initIpcServer()这个方法。另外其中还有initDataXceiver()方法用来处理DataNode传输packet的过程,后续分析HDFS读写流程会详细展开。
接着继续createDataNode方法中的runDatanodeDaemon,这里主要是启动RPC服务和dataXceiverServer。
三、Datanode 注册流程分析
这里主要分析下startDataNode中的一个比较重要的流程,注册和心跳:
blockPoolManager = new BlockPoolManager(this);
blockPoolManager.refreshNamenodes(getConf());
说明:一个集群只有一个BlockPool,如果是联邦模式才会有多个。
org.apache.hadoop.hdfs.server.datanode.BlockPoolManager#refreshNamenodes
org.apache.hadoop.hdfs.server.datanode.BlockPoolManager#doRefreshNamenodes
org.apache.hadoop.hdfs.server.datanode.BlockPoolManager#createBPOS
org.apache.hadoop.hdfs.server.datanode.BPOfferService#BPOfferService
这里观察BPOfferService构造方法
for (int i = 0; i < nnAddrs.size(); ++i) {
this.bpServices.add(new BPServiceActor(nnAddrs.get(i),
lifelineNnAddrs.get(i), this));
}
构造BPServiceActor对象,加入到列表中,因为此流程本身也是在一个for循环中的,所以说明对于每个 BPOfferService 对象有一个 BPServiceActor 类型的列表。
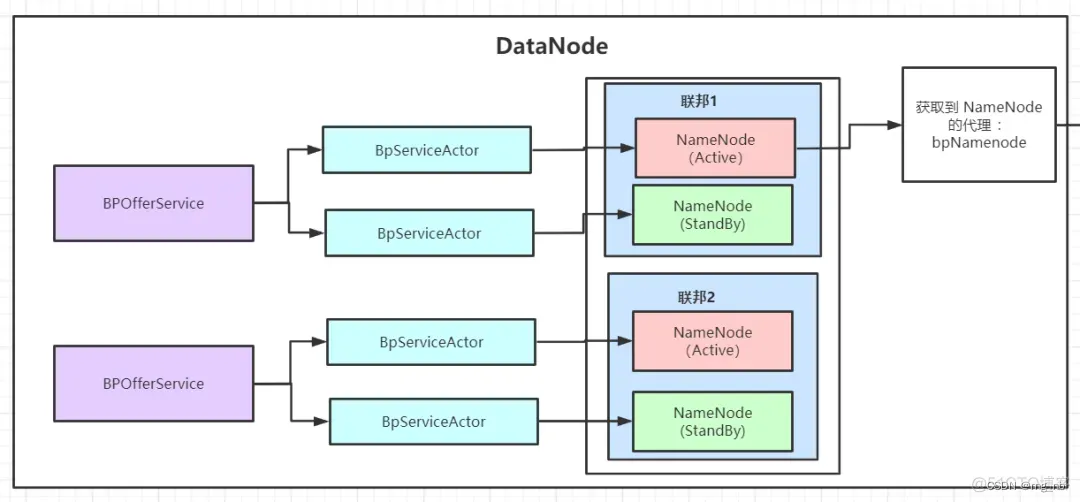
引用别人的图来解释一下
每个 BPOfferService 里面有两个 BpServiceActor,每个 BpServiceActor 对应一个 NameNode
如果是上图中的高可用,那么一主一备两个 NameNode,分别对应一个 BpServiceActor。
所以遍历 offerService 其实就是在遍历整个集群每个联邦的每个 NameNode 节点。
接着来到startAll()方法,startAll() 中又是一个循环,可以看出,这里其实就是调用了每个 BPOfferService对象的start方法
synchronized void startAll() throws IOException {
try {
UserGroupInformation.getLoginUser().doAs(
new PrivilegedExceptionAction<Object>() {
@Override
public Object run() throws Exception {
for (BPOfferService bpos : offerServices) {
bpos.start();
}
return null;
}
});
} catch (InterruptedException ex) {
IOException ioe = new IOException();
ioe.initCause(ex.getCause());
throw ioe;
}
}
继续往下走
org.apache.hadoop.hdfs.server.datanode.BlockPoolManager#startAll
org.apache.hadoop.hdfs.server.datanode.BPOfferService#start
org.apache.hadoop.hdfs.server.datanode.BPServiceActor#start
org.apache.hadoop.hdfs.server.datanode.BPServiceActor#run
org.apache.hadoop.hdfs.server.datanode.BPServiceActor#connectToNNAndHandshake
org.apache.hadoop.hdfs.server.datanode.BPServiceActor#register
org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB#registerDatanode
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer#registerDatanode
org.apache.hadoop.hdfs.server.namenode.FSNamesystem#registerDatanode
org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#registerDatanode
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager#registerDatanode
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager#addDatanode
中间经过的RPC调用,最后到addDatanode方法里,此方法对一些集合赋值(datanodeMap,host2DatanodeMap,networktopology)
四、心跳流程分析
继续接着上一节的BPServiceActor的run()方法后续,其中offerService()方法为心跳流程
while (shouldRun()) {
try {
offerService();
} catch (Exception ex) {
LOG.error("Exception in BPOfferService for " + this, ex);
sleepAndLogInterrupts(5000, "offering service");
}
}
org.apache.hadoop.hdfs.server.datanode.BPServiceActor#run
org.apache.hadoop.hdfs.server.datanode.BPServiceActor#offerService
org.apache.hadoop.hdfs.server.datanode.BPServiceActor#sendHeartBeat
org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB#sendHeartbeat
org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolServerSideTranslatorPB#sendHeartbeat
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer#sendHeartbeat
org.apache.hadoop.hdfs.server.namenode.FSNamesystem#handleHeartbeat
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager#handleHeartbeat
org.apache.hadoop.hdfs.server.blockmanagement.HeartbeatManager#updateHeartbeat
org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#updateHeartbeat
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeDescriptor#updateHeartbeat
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeDescriptor#updateHeartbeatState
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeDescriptor#updateStorageStats
在updateStorageStats中更新了DatanodeInfo的信息
最后在会将DatanodeCommand数组设置到HeartbeatResponse