一、构建Pipeline
在从客户端提交写入文件的请求后,NameNode需要选择出一些适合的DataNode,将这些DataNode放入一个Pipeline中。NameNode会与Pipeline中的第一个DataNode交互(发送Packet),接下来第一个DataNode会将Packet发送到Pipeline中的第二个DataNode,以此类推直到最后一个DataNode。当Pipeline中的最下游节点收到数据包后,会按照数据包传送方向的反方向发送对数据包的Ack信息。这个Ack信息是一个数据包的序列号,在Client侧是单调递增的。参考下图: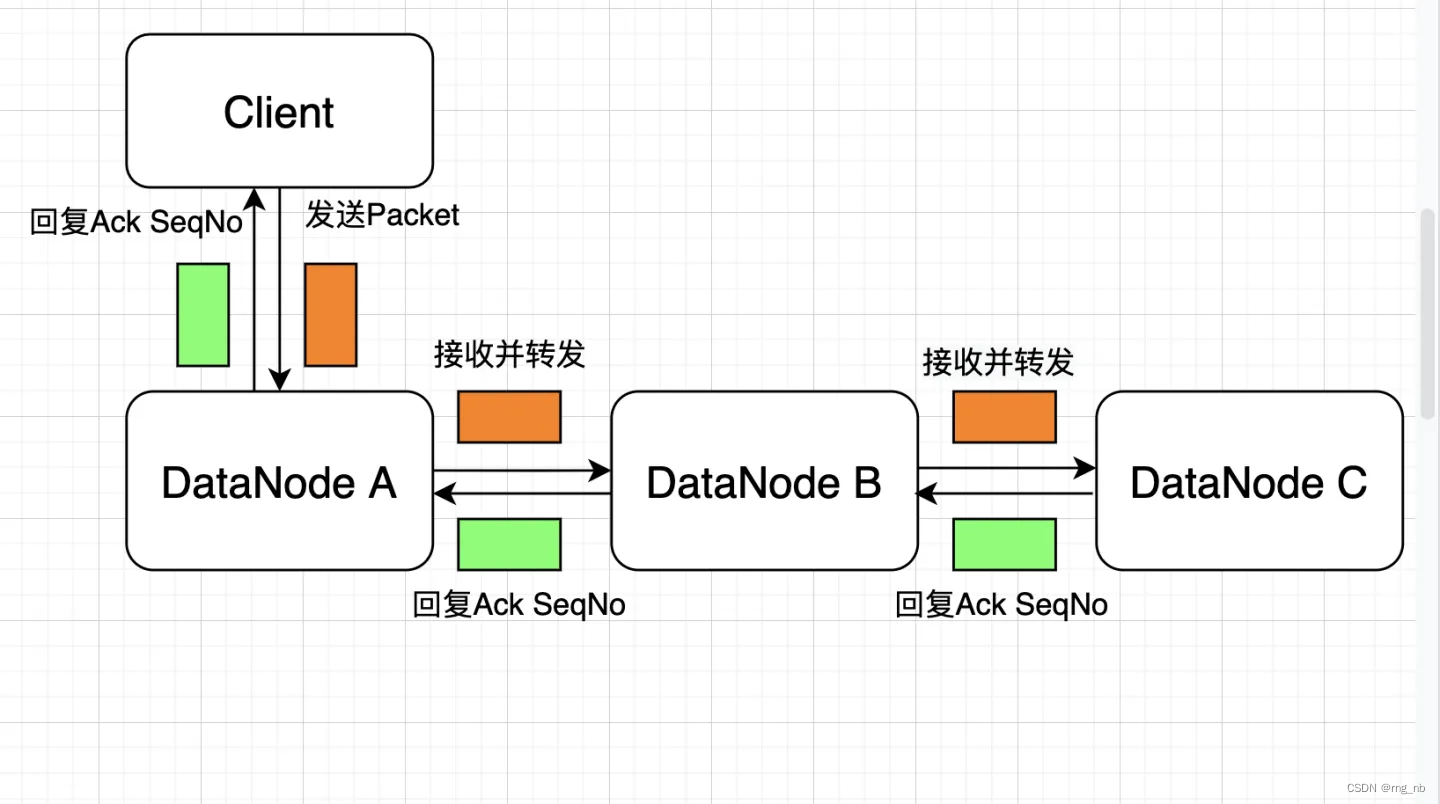
二、DFSOutputStream的构建
//常规使用客户端向HDFS写入数据的代码片段,接下来来以此分析
FSDataOutputStream out = dfs.create(new Path("/a/b/c.txt"));
out.write("abc".getBytes());
调用栈如下
org.apache.hadoop.fs.FileSystem#create(Path)
org.apache.hadoop.fs.FileSystem#create(Path, boolean)
org.apache.hadoop.fs.FileSystem#create(Path, boolean, int, short, long)
org.apache.hadoop.fs.FileSystem#create(Path, boolean, int, short, long, Progressable)
org.apache.hadoop.hdfs.DistributedFileSystem#create(Path, FsPermission, boolean, int, short, long, Progressable)
org.apache.hadoop.hdfs.DistributedFileSystem#create(Path, FsPermission, EnumSet<CreateFlag>, int, short, long, Progressable, Options.ChecksumOpt)
可以看到此阶段使用了很多重载方法,最后走到DistributedFileSystem的create方法,我们来看下代码
public FSDataOutputStream create(final Path f, final FsPermission permission,
final EnumSet<CreateFlag> cflags, final int bufferSize,
final short replication, final long blockSize,
final Progressable progress, final ChecksumOpt checksumOpt)
throws IOException {
statistics.incrementWriteOps(1);
storageStatistics.incrementOpCounter(OpType.CREATE);
Path absF = fixRelativePart(f);
return new FileSystemLinkResolver<FSDataOutputStream>() {
@Override
public FSDataOutputStream doCall(final Path p) throws IOException {
final DFSOutputStream dfsos = dfs.create(getPathName(p), permission,
cflags, replication, blockSize, progress, bufferSize,
checksumOpt);
return dfs.createWrappedOutputStream(dfsos, statistics);
}
@Override
public FSDataOutputStream next(final FileSystem fs, final Path p)
throws IOException {
return fs.create(p, permission, cflags, bufferSize,
replication, blockSize, progress, checksumOpt);
}
}.resolve(this, absF);
}
最后的resolve的方法会触发其中的doCall方法,那继续看下其中做了什么
public DFSOutputStream create(String src, FsPermission permission,
EnumSet<CreateFlag> flag, boolean createParent, short replication,
long blockSize, Progressable progress, int buffersize,
ChecksumOpt checksumOpt, InetSocketAddress[] favoredNodes,
String ecPolicyName) throws IOException {
checkOpen();
final FsPermission masked = applyUMask(permission);
LOG.debug("{}: masked={}", src, masked);
final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this,
src, masked, flag, createParent, replication, blockSize, progress,
dfsClientConf.createChecksum(checksumOpt),
getFavoredNodesStr(favoredNodes), ecPolicyName);
beginFileLease(result.getFileId(), result);
return result;
}
原来是走到了DFSClient的create方法,这里创建了一个DFSOutputStream流对象。参数比较多,其中的this代表DFSClient对象,还有favoredNodes列表代表优先选择的DataNode。这里重点关注下newStreamForCreate方法,在newStreamForCreate方法中主要做两个工作:
① 调用Namenode代理对象上的create方法,在NameNode文件系统中创建一个文件,并获得此文件的元数据信息HdfsFileStatus对象。
② 将①中的HdfsFileStatus对象传入DFSOutputStream构造方法中,构造出一个DFSOutputStream流对象,同时启动DFSOutputStream对象中的DataStreamer线程。
对于步骤① 调用栈如下,可以看到其实创建文件跟创建目录类似,就是在 FSDirectory 对象的相应节点上在添加一个INodeFile节点
org.apache.hadoop.hdfs.DFSOutputStream#newStreamForCreate
org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer#create
org.apache.hadoop.hdfs.server.namenode.FSNamesystem#startFile
org.apache.hadoop.hdfs.server.namenode.FSNamesystem#startFileInt
org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp#startFile
org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp#addFile
org.apache.hadoop.hdfs.server.namenode.FSDirWriteFileOp#newINodeFile
org.apache.hadoop.hdfs.server.namenode.INodeFile#INodeFile
org.apache.hadoop.hdfs.server.namenode.FSDirectory#addINode
org.apache.hadoop.hdfs.server.namenode.FSDirectory#addLastINode
org.apache.hadoop.hdfs.server.namenode.INodeDirectory#addChild
到这里创建完INodeFile和启动了名为DataSteamer的线程后DFSOutputStream的构建也就完成了。
三、DataStreamer
DataStreamer是Client写数据的核心类。它本质上是个Thread类。它的主要功能在JavaDoc中描述的很详细,这里摘录一下:
/*********************************************************************
*
* The DataStreamer class is responsible for sending data packets to the
* datanodes in the pipeline. It retrieves a new blockid and block locations
* from the namenode, and starts streaming packets to the pipeline of
* Datanodes. Every packet has a sequence number associated with
* it. When all the packets for a block are sent out and acks for each
* if them are received, the DataStreamer closes the current block.
*
* The DataStreamer thread picks up packets from the dataQueue, sends it to
* the first datanode in the pipeline and moves it from the dataQueue to the
* ackQueue. The ResponseProcessor receives acks from the datanodes. When an
* successful ack for a packet is received from all datanodes, the
* ResponseProcessor removes the corresponding packet from the ackQueue.
*
* In case of error, all outstanding packets are moved from ackQueue. A new
* pipeline is setup by eliminating the bad datanode from the original
* pipeline. The DataStreamer now starts sending packets from the dataQueue.
*
*********************************************************************/
翻译:
DataStreamer类负责给在pipeline中的datanode发送数据包。它从namenode检索一个新的blockid和block位置,并开始把数据包以流的形式发送到datanodes组成的pipeline中。每个数据包都有一个与之相关联的序列号。当一个块的所有包都被发送出去并且每个包的ack信息也都被收到,则DataStreamer会关闭当前块。
DataStreamer线程从dataQueue中提取数据包,并将数据包发送到将管道中的第一个datanode,然后把这个数据包从dataQueue移动到ackQueue。ResponseProcessor线程接收来自datanode的响应。当一个数据包的成功的ack信息从所有datanode发送过来时,ResponseProcessor会从ackQueue中移除相应的数据包。
在出现错误的情况下,所有未完成的数据包将从ackQueue中被移除。接着在原来的出错的pipeline中消除掉bad datanode的基础上构建一个新的pipeline。DataStreamer再继续开始发送dataQueue中的数据包。
对于步骤② ,因为启动了名为DataSteamer的线程,所以我们直接看下其中的run方法,由于run方法行数较多,所以只解释说明重要的点。
问题1:wait的参数timeout时间是怎么确定的?
为什么需要wait呢?看while的条件:
while ((!shouldStop() && dataQueue.size() == 0 &&
(stage != BlockConstructionStage.DATA_STREAMING ||
now - lastPacket < halfSocketTimeout)) || doSleep) {
long timeout = halfSocketTimeout - (now-lastPacket);
timeout = timeout <= 0 ? 1000 : timeout;
timeout = (stage == BlockConstructionStage.DATA_STREAMING)?
timeout : 1000;
try {
dataQueue.wait(timeout);
} catch (InterruptedException e) {
LOG.warn("Caught exception", e);
}
doSleep = false;
now = Time.monotonicNow();
}
dataQueue的size是0,证明没有数据需要发送,因此不需要执行后面的发送逻辑,所以线程可以wait进入等待状态。至于为什么要用halfSocketTimeout这个值,我觉得单纯是HDFS这块开发者做的一个trade-off,你也可以减小这个值,这样无非就是多发送几个heartbeat Packet而已。(而且,最新的HDFS社区代码这里已经移除了wait halfSocketTimeout的逻辑)。
做个简单的数学计算 long timeout = halfSocketTimeout - (now-lastPacket);
timeout = timeout <= 0 ? 1000 : timeout; 那如果timeout>0实际上结束wait的时间是:
now + timeout = now + halfSocketTimeout - now + lastPacket = lastPacket + halfSocketTimeout;
也即保证在上一个Packet包发送后,在wait至少halfSocketTimeout时长。
问题2:如何构建的DN网络连接,Pipeline
先看下run方法中相关的代码,重点在setPipeline方法和nextBlockOutputStream()方法
// get new block from namenode.
if (LOG.isDebugEnabled()) {
LOG.debug("stage=" + stage + ", " + this);
}
if (stage == BlockConstructionStage.PIPELINE_SETUP_CREATE) {
LOG.debug("Allocating new block: {}", this);
setPipeline(nextBlockOutputStream());
initDataStreaming();
} else if (stage == BlockConstructionStage.PIPELINE_SETUP_APPEND) {
LOG.debug("Append to block {}", block);
setupPipelineForAppendOrRecovery();
if (streamerClosed) {
continue;
}
initDataStreaming();
}
先说下nextBlockOutputStream()方法,其内部做了两件事:
- 客户端调用addBlock这个RPC增加一个数据块,并返回LocatedBlock对象,此对象包含了block的元信息。(入口为locateFollowingBlock方法)
- 客户端使用随机接口与列表中的第一个DataNode建立Socket连接,通过连接获取到的DataOutputStream来构造一个DataSender对象,调用DataSender的writeBlock方法(入口为createBlockOutputStream方法)。
在[[HDFS]-[源码分析]-DataNode启动流程](https://blog.csdn.net/rng_nb/article/details/133298277)一文中,有提到在startDataNode时会初始化一个DataXceiverServer,这里详细说一下
xserver = new DataXceiverServer(tcpPeerServer, getConf(), this);
this.dataXceiverServer = new Daemon(threadGroup, xserver);
可以看到DataXceiverServer是Runnable的实现类,所以直接看一下其run方法,其中又初始化了一个DataXceiver类并且此类也是Runnable的实现类。
new Daemon(datanode.threadGroup,
DataXceiver.create(peer, datanode, this))
.start();
所以直接看DataXceiver的run方法,这里起了一个线程监听客户端的Socket请求并处理,会从流中读出操作码(Op),调用processOp方法来处理,这里对应的就是WRITE_BLOCK,最终会调用DataXceiver的writeBlock方法。
//接收流
IOStreamPair saslStreams = datanode.saslServer.receive(peer, socketOut,
socketIn, datanode.getXferAddress().getPort(),
datanode.getDatanodeId());
input = new BufferedInputStream(saslStreams.in,
smallBufferSize);
socketOut = saslStreams.out;
...
//处理流中对应的操作
op = readOp();
processOp(op);
也就是说DataSender的writeBlock请求会被DataXceiver的writeBlock方法接收并处理。
接下来先讲下如何与后续的DataNode节点建立连接的再讲block是如何被接收的。
在DataXceiver的writeBlock方法可以看到如下代码
DataOutputStream mirrorOut = null; // stream to next target
DataInputStream mirrorIn = null; // reply from next target
Socket mirrorSock = null; // socket to next target
String mirrorNode = null; // the name:port of next target
String firstBadLink = ""; // first datanode that failed in connection setup
...
if (targets.length > 0) {
InetSocketAddress mirrorTarget = null;
// Connect to backup machine
mirrorNode = targets[0].getXferAddr(connectToDnViaHostname);
LOG.debug("Connecting to datanode {}", mirrorNode);
mirrorTarget = NetUtils.createSocketAddr(mirrorNode);
mirrorSock = datanode.newSocket();
try {
...
NetUtils.connect(mirrorSock, mirrorTarget, timeoutValue);
...
IOStreamPair saslStreams = datanode.saslClient.socketSend(
mirrorSock, unbufMirrorOut, unbufMirrorIn, keyFactory,
blockToken, targets[0], secretKey);
unbufMirrorOut = saslStreams.out;
unbufMirrorIn = saslStreams.in;
mirrorOut = new DataOutputStream(new BufferedOutputStream(unbufMirrorOut,
smallBufferSize));
mirrorIn = new DataInputStream(unbufMirrorIn);
...
if (targetPinnings != null && targetPinnings.length > 0) {
new Sender(mirrorOut).writeBlock(originalBlock, targetStorageTypes[0],
blockToken, clientname, targets, targetStorageTypes,
srcDataNode, stage, pipelineSize, minBytesRcvd, maxBytesRcvd,
latestGenerationStamp, requestedChecksum, cachingStrategy,
allowLazyPersist, targetPinnings[0], targetPinnings,
targetStorageId, targetStorageIds, file);
} else {
new Sender(mirrorOut).writeBlock(originalBlock, targetStorageTypes[0],
blockToken, clientname, targets, targetStorageTypes,
srcDataNode, stage, pipelineSize, minBytesRcvd, maxBytesRcvd,
latestGenerationStamp, requestedChecksum, cachingStrategy,
allowLazyPersist, false, targetPinnings,
targetStorageId, targetStorageIds, file);
}
...
}
是不是感觉很熟悉,这里的逻辑和createBlockOutputStream方法中一样,也是再次构造了一个Sender对象来writeBlock,这样循环往复直到targets.length=0。
四、Pipeline中Block的接收和Ack返回
上面提到过,DataStream线程从dataQueue队列中取出待发送的DFSPacket对象时,会把packet加入到ackQueue中,表示此Packet需要等待pipeline中的DataNode都返回ACK信息。那DataNode是如何给上游的DataNode以及Client返回Ack信息的呢?下面我们就来看看。
在DataStreamer中不是调用了new Sender(xxx).writeBlock方法么?这个东西会被DataNode侧的DataXceiver类中的writeBlock方法处理。writeBlock方法中又会委托给BlockReceiver#receiveBlock方法。receiveBlock方法中启动了PacketResponder线程用来对接收到的packet进行响应。
观察一下receiveBlock方法的参数:
DataOutputStream mirrOut, // output to next datanode
DataInputStream mirrIn, // input from next datanode
DataOutputStream replyOut, // output to previous datanode
这三个流分别代表给下游datanode发送数据的输出流、接收下游datanode数据的输入流、以及回复上游数据的输出流。看一下PacketResponder的构造函数,将其中的两个流传入作为参数了:
if (isClient && !isTransfer) {
responder = new Daemon(datanode.threadGroup,
new PacketResponder(replyOut, mirrIn, downstreams));
responder.start(); // start thread to processes responses
}
this.type = downstreams == null? PacketResponderType.NON_PIPELINE
: downstreams.length == 0? PacketResponderType.LAST_IN_PIPELINE
: PacketResponderType.HAS_DOWNSTREAM_IN_PIPELINE;
初始化PacketResponder对象时中的type表示此responder是pipeline中的最后一个节点还是中间节点。
回到receiveBlock里,会有这样一行代码:
while (receivePacket() >= 0) { /* Receive until the last packet */ }
这是一个空循环,只要还有数据过来,那就一直调用receivePacket方法。这个receivePacket方法返回的是接收的数据字节数。里面会从输入流中读取Packet的各种信息,然后入队,等待packet线程后台去处理
// put in queue for pending acks, unless sync was requested
if (responder != null && !syncBlock && !shouldVerifyChecksum()) {
((PacketResponder) responder.getRunnable()).enqueue(seqno,
lastPacketInBlock, offsetInBlock, Status.SUCCESS);
}
那接下来就是看PacketResponeder怎么给上游的DataNode或者Client返回响应的吧。其实是在PacketResponeder线程的run方法中最终调用了sendAckUpstreamUnprotected方法给上游发送Ack 。
BlockReceiver.PacketResponder#run
sendAckUpstream(ack, PipelineAck.UNKOWN_SEQNO, 0L, 0L,
PipelineAck.combineHeader(datanode.getECN(),
Status.SUCCESS,
datanode.getSLOWByBlockPoolId(block.getBlockPoolId())));
BlockReceiver.PacketResponder#sendAckUpstreamUnprotected
replyAck.write(upstreamOut);
OK,到这里我们也就知道了DataNode是如何回复Ack信息的了。